Software Architecture, Data Models & Netflix

Introduction
Software Architects need to get better at data modeling, for two high-level reasons:
Simplicity - data models should support (not hinder) the development lifecycle.
Performance - thoughtful data models can accelerate development velocity and application performance (sometimes by orders of magnitude, as below).
In this article, I’m going to walk through a real-world data modeling effort that contributed to significant performance optimization (10x to 200x) of a critical CRM application at one of the major movie studios, also demonstrating how much simpler development can be for teams that embrace data modeling as a discipline.
(This article is essentially a sequel to a talk I gave, called Data Engineering as Software Engineering, although that talk is not a prerequisite for this article. I gave the talk to Joe Reis’ Practical Data Discord Community, which you should join.)
The article is organized as follows:
First, I’ll discuss the supply side of the Media & Entertainment (M&E) business model, i.e. how major M&E companies like Netflix acquire their product (i.e. content).
Next, I’ll map this content acquisition model to its corresponding data model, showing how content procurement is modeled and managed in a CRM system for M&E companies, with a nod toward the four hierarchies that drive content sales.
I’ll then introduce the high-level business logic that operates on that data model as sellers and buyers negotiate contracts, specifically highlighting the performance bottleneck(s) that result from inefficient data models.
Finally, I’ll demonstrate how the data model for CRM hierarchies can be refactored to introduce simpler and faster code, also addressing the architectural and political implications of Conway’s Law that likely need to be overcome in order to realize success on such projects.
I won’t be diving deep into the formalities of various data modeling paradigms, but I will encourage the reader to keep traditional OLTP and OLAP paradigms in mind, as the solution I’ll be reviewing arises from the confluence of these two traditions. Again, effective application architecture and development relies on Software Architects not only being well-trained on traditional data modeling approaches, but also extending these approaches into more creative solutions when solving for novel optimization problems.
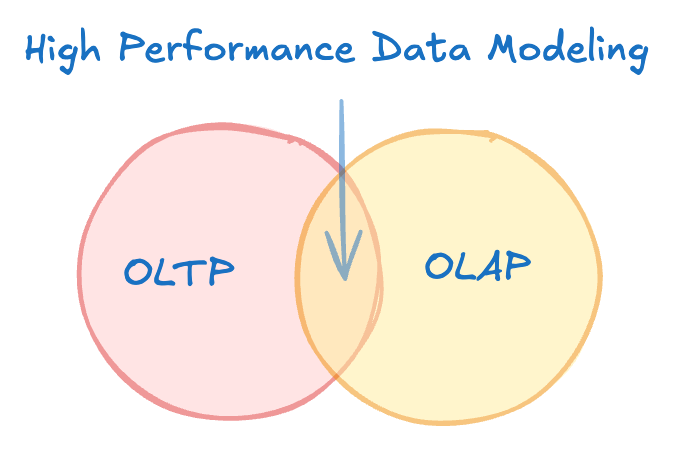
Business Model
Major studios like Netflix show two types of content:
In-house content
Licensed content
For licensing content from - and to - other studios, the process usually goes as follows:
A buyer from a media company calls a studio, asking about certain content that they would like to license. It could be a movie, a TV series, or even just a specific season or episode (generically referred to as an IP).

Friends is owned by Warner Bros. The entire series has been leased to Netflix. The production company sales rep asks for what specific criteria they have in mind:
When would they like to show the IP?
IPs are licensed for specific periods of time In which territories?

IPs are licensed for specific territories (regions) And in which language(s)?

IPs are licensed for specific languages And lastly, in which media (also called “market”) format, i.e. on-demand, live, DVD, etc.

The sales rep then enters the buyer’s criteria into their CRM system to check for availability, i.e. to make sure there aren’t contracts with other customers that would prevent this deal from going through (depending on exclusivity conditions, discussed further below) .




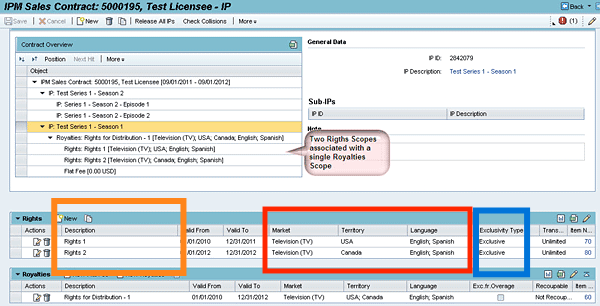
And if you want to see what this looks like from the seller’s CRM, here’s an example screenshot from SAP’s CRM Intellectual Property Management (IPM) solution showing
the IP parameters in orange,
the Market (Media) / Territory / Language parameters in red,
the Exclusivity Types in blue.
Data Model
The basic data model for sales contract lines can be gleaned from the prior screenshot. Just the relevant fields are included below, which are mostly foreign keys that point to corresponding hierarchies.
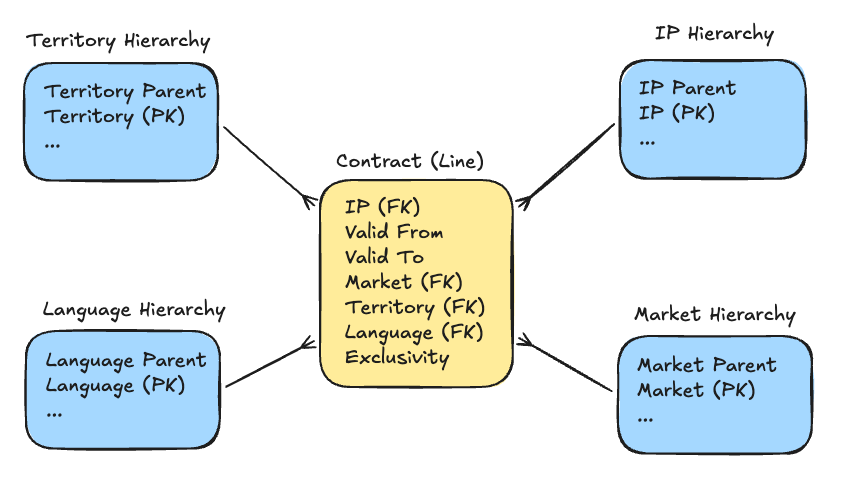
(In reality, different hierarchies are often persisted in the same physical table, but it’s easier to represent as conceptually distinct - which is fine for the purposes of this article.)
Hierarchies
The crux of the performance problem that we’ll be discussing is how hierarchies are modeled and traversed in the context of the business model described above, i.e. how a seller checks for any pre-existing contract lines that would preclude the deal from closing.
This process is called “Rights Availability” within the CRM IPM application, i.e. checks if rights to a particular IP are available to be leased to a customer.
Before getting into the technical details, it’s worth briefly touching on the four major hierarchies involved:
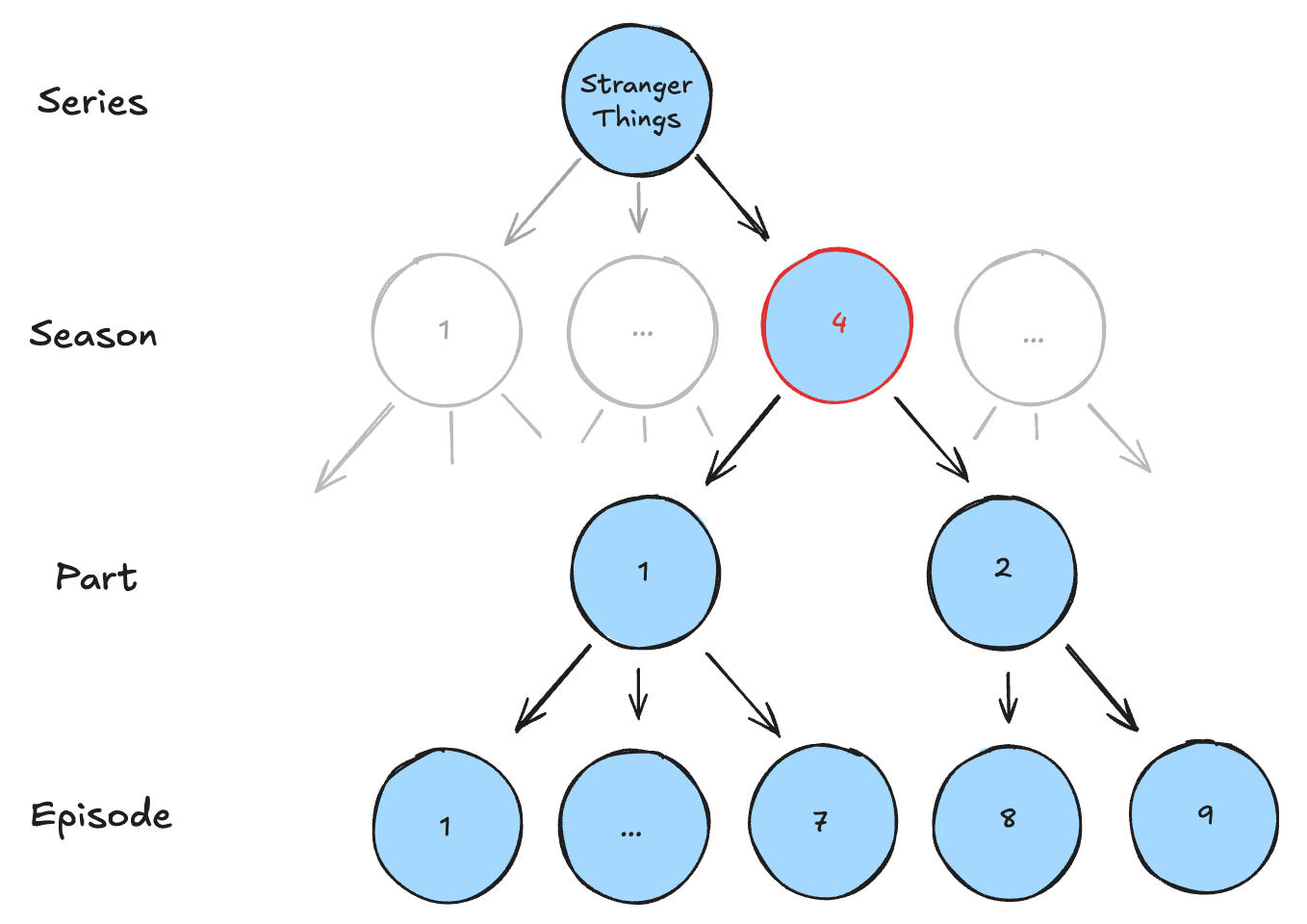
IP Hierarchy - Usually a three-level hierarchy (Series → Season → Episode) with some exceptions (i.e. consider Seasons 4 and 5 of Stranger Things, which further split seasons into multiple parts, which then contain various episodes).
Territory Hierarchy - The number of levels varies, i.e. could include things like regions, states, counties, townships, and/or country-specific postal codes.
Language Hierarchy - Most folks are familiar with language dialects that form hierarchies, i.e. British English vs. American English. Language hierarchies can get more complex in standards such as BCP 47.
Market Hierarchy - probably the most complicated of the hierarchies. Here’s a partial industry example below.

The main point here is that in a majority of cases, each of the hierarchies described above can be of arbitrary depth (i.e. N number of levels) which means the data model should flexibly accommodate varying hierarchy types of varying depths.
I’ll walk through the standard OLTP data model that accommodates hierarchies in this fashion, sticking with the Stranger Things IP hierarchy below as an example (node colors correspond with the data model examples further down).
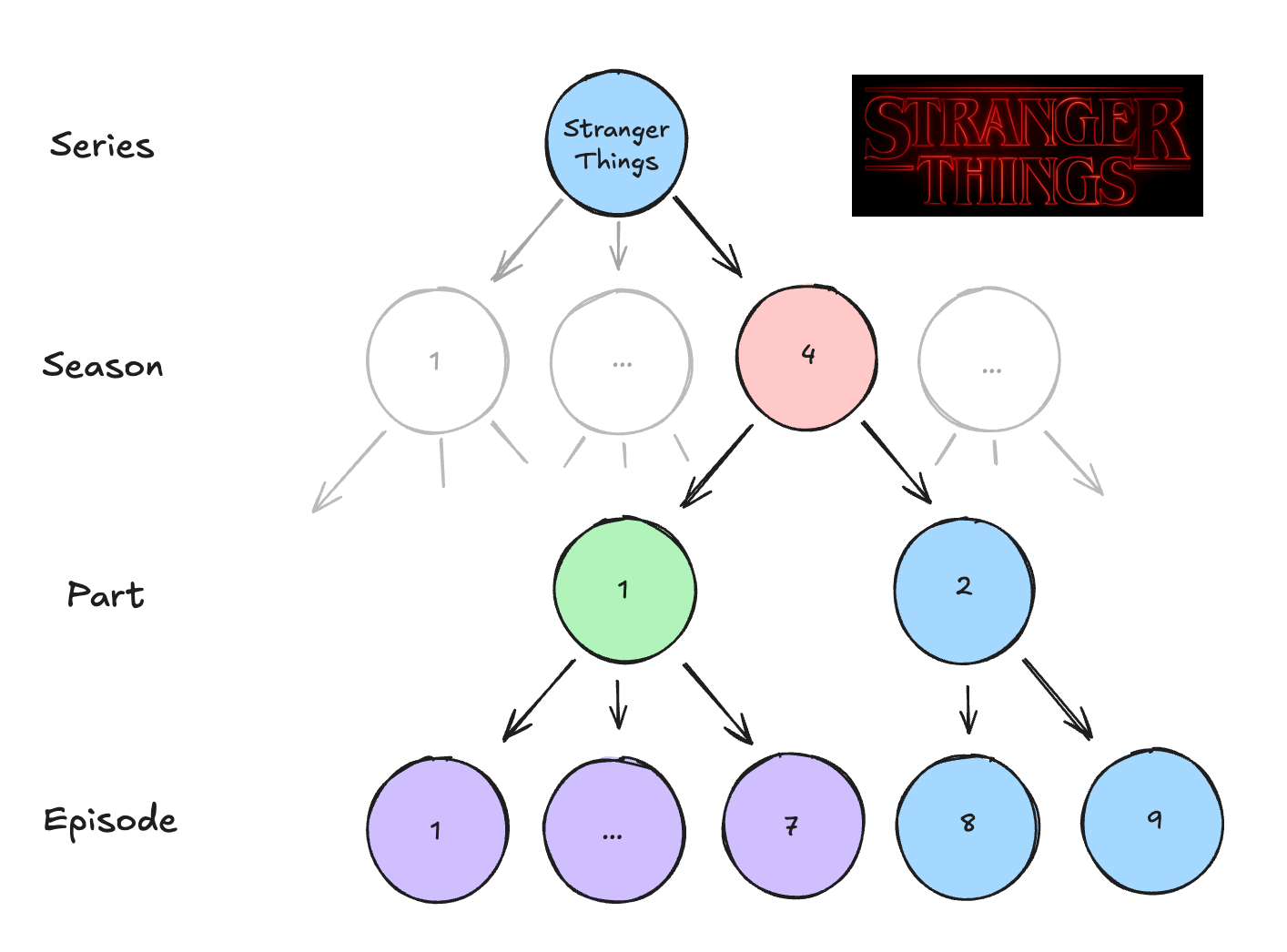
I’ll then highlight performance headaches that the standard OLTP hierarchy data model introduces (and more importantly, the cognitive friction it introduces that leads to bad algorithm design).
Hierarchies (OLTP)
The basic model for storing hierarchical data in a transactional (OLTP) context is a parent-child model, also sometimes referred to as an adjacency list. In short, it captures each “edge” in the hierarchy, i.e. each relationship between a parent node and a child node (in the left-hand table below).
Note that this model easily accommodates any number of levels of hierarchy nodes, i.e. is quite flexible for managing any kind of hierarchy inserts / updates / deletes without have to change the model.

Business Logic
Let’s translate the business model discussed above into the corresponding business logic implemented within the CRM IPM Rights Availability feature. We’ll again use Stranger Things as our example.
You may recall that Stranger Things - Season 5 was released on Netflix, with the season finale (Episode 8) also released in a handful of theaters across the country.
Let’s now imagine a theoretical negotiation that might’ve taken place last year in light of the release of Season 5.
Imagine you’re in charge of content for In-Flight Entertainment (IFE) for Canada’s largest airline, Air Canada.
You know that Stranger Things is releasing its final season,
You want to capitalize on the expected high demand to help drive more airline ticket sales given your high-quality IFE offerings, by leasing the entire Season 4 (i.e. so that fans can get back up to speed on the latest storyline developments),
You want exclusive rights to the entire series, for a 3-month window, but
You only care about the high-traffic region of Central Canada and New England, i.e. to capture the busy flight schedule between Toronto, Montreal, New York and Boston, and lastly
Want to include all available languages to accommodate the relatively diverse languages spoken in this region of the world.
(For illustration purposes, we’ll also add some pre-existing contract lines to the sample data below in the Contract Lines table.)
So, you call up the Netflix sales rep, share the deal parameters above, and the sales rep enters them into his system (represented below, along with contract lines already in the system).
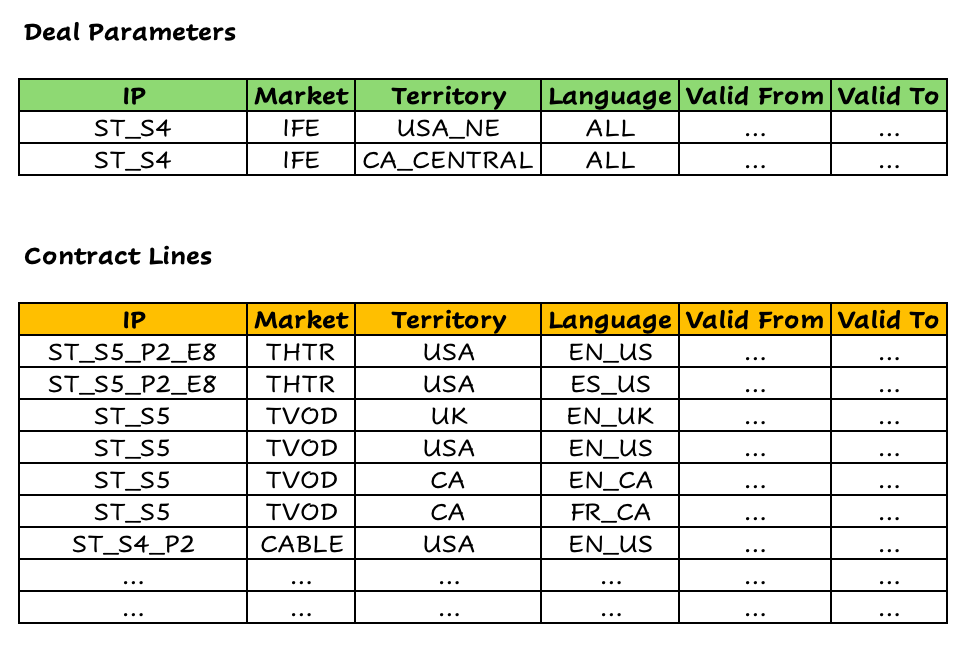
The business logic for Rights Availability in the CRM IPM application basically just involves comparing the Deal Parameters data with the Contract Lines, and checking if there’s any overlap that would conflict with any exclusivity clauses (either in deals already sold, or in the deal being negotiated).
If you squint your eyes at the data above, you can kind of work out what the system will find when doing this check:
Part 2 of Season 4 has already been leased
To a cable company
For the entire USA
In US English
What’s relatively obvious is where there are conflicts at different nodes along the same paths of the respective hierarchies.
For example, the existing contract line for Season 4 Part 2 will, of course, conflict with any attempt to exclusively lease the entire Season 4 to Air Canada.
However, if a hierarchy node is found along a different path than what’s being searched, i.e. if the Cable market is entirely separate from the path for IFE, then there is no conflict. And this makes sense. An airline probably isn’t going to consider cable companies as competitors for their in-flight entertainment (especially given the atrocious WiFi speeds of most airplanes which wouldn’t support any cable streaming options either).
So, conceptually, the business logic is fairly clear:
Compare all existing contract lines to the deal parameters, and see if there are conflicts, by checking for “similar” records (per hierarchy).
But now imagine you’re the developer writing the code that does this comparison, i.e. between deal terms and contract lines.
How do you do so efficiently (and elegantly)?
The Problem: Performance Bottleneck
Put your self in the shoes of the developer / architect that designs the algorithm for the business logic described above. What you essentially have to do is:
compare records across two multidimensional datasets (i.e. risk of a nested
forloop, which compounds for for each additional deal parameter entered, of which there could be 10 or 20),with recursive logic to traverse four different hierarchies, both up and down,
which is mostly like done in application code (where developers are much more comfortable, as opposed to recursive CTEs in SQL),
which requires sending entire tables over the wire to load into memory,
which probably also means having to iterate over the entire Contract Lines table (unless the developers cleverly build lists of values from the recursive lookups executed above, that they then would need to append to a WHERE clause sent back to the database for the contract lines - which, they didn’t, in the real-world project I was on)
and it gets even worse when you have to stitch together 5 tables from a hideous data model just to retrieve a single parent-child hierarchy (i.e. in the case of SAP).
(And we haven’t even gotten to the surprising complexity of the date overlap logic, i.e. comparing date intervals in the contract lines with the date interval(s) requested in the deal parameters…)
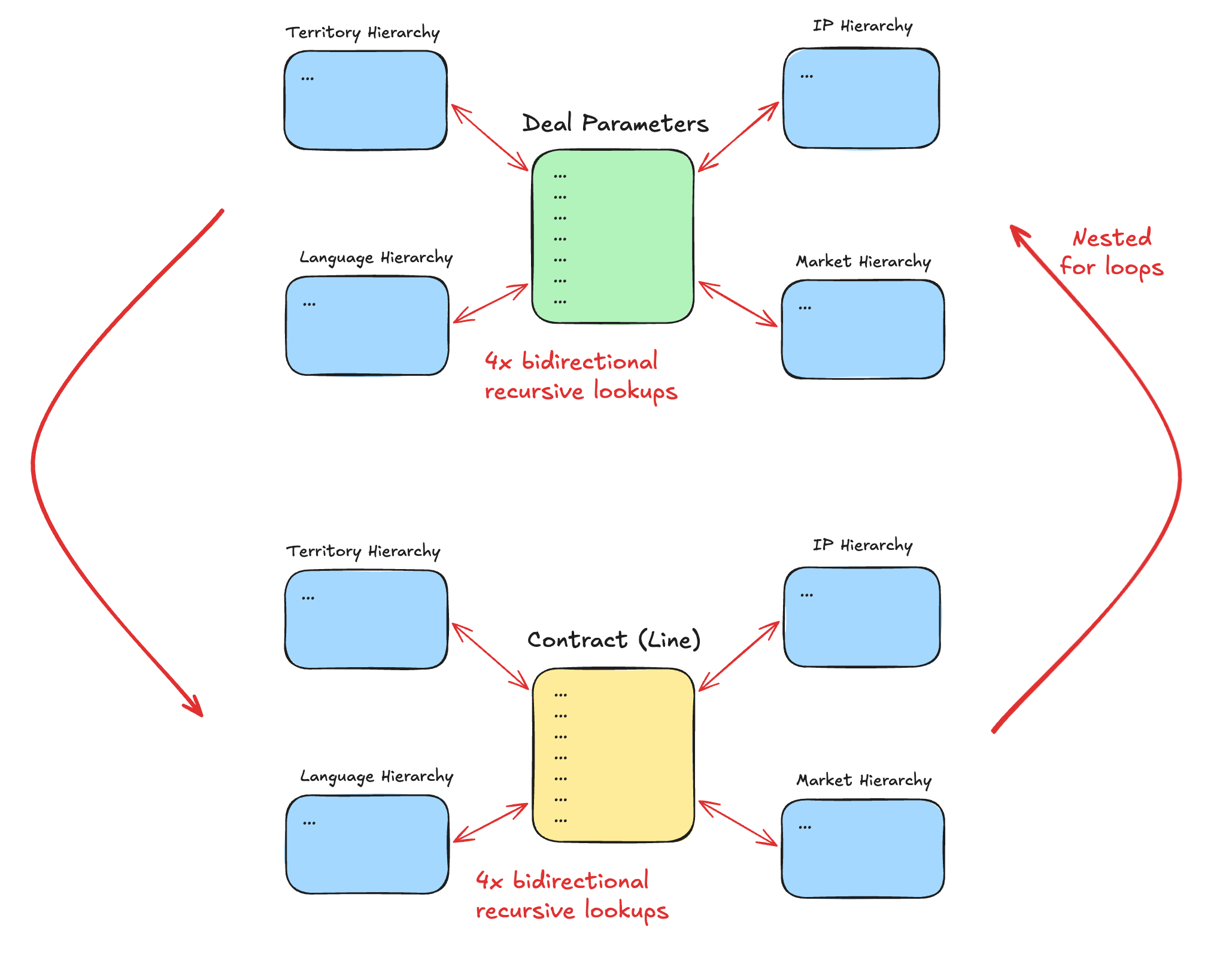
My point here is to elicit a bit of empathy for the poor developers who are expected to make a silk bag out of a sow’s ear (to use a very old school expression).
In other words, developers are often not setup for success; hence why I’m making the case that their respective Architects / Team Leads should be responsible for thinking through alternative data models and architectures that can then empower them to write code that is both elegant and efficient. And as demonstrated above, a traditional OLTP parent-child hierarchy data model is not the way to get there.
The Solution: A Better Data Model
A major component of the overall solution for the performance bottleneck described above is the introduction of a hierarchy data model that I’m calling the “node lineage” data model.
The purpose of the model is essentially to:
Significantly reduce the number of records iterated over from the Contract Lines table by providing a straightforward filter against relevant records regardless of where in each hierarchy the corresponding node values are (i.e. the foreign key values of Market / Territory / Language / IP)
Reduce the computational overhead (and code complexity) of loading tables into memory and recursively traversing them “manually”.
Worth noting is that in the problem statement above, we actually already described what the target model should look like:
“…what’s relatively obvious is where there are conflicts at different nodes along the same paths of the respective hierarchies…”
In other words, we want a model that maps any given node (i.e. Season 4 in the IP hierarchy table) to all of the corresponding upstream and downstream nodes along the same path.
Here’s a modified version of the hierarchy we looked at earlier, highlighting the nodes that should be mapped against Season 4 of Stranger Things (i.e. the requested IP from a buyer at Air Canada).
And here is what the corresponding hierarchy lineage data model would look like, with a few additional attributes (in grey) that could come in handy.

What this table allows us to do is to drastically simplify the query logic when searching contract lines for any conflicts (as required when trying to negotiate exclusive deals) across the IP hierarchy, given that all upstream/downstream nodes (i.e. what I’m calling the node lineage) are mapped directly to each node.
In other words, the recursive search logic has been “denormalized” (I’m taking liberties here with this term, which I think captures the gist of what’s going on), which is a quite reasonable thing to do. No need executing this recursive logic thousands of times a day as studio sellers negotiate contracts all day long.
(This “denormalization” is conceptually similar to the “denormalized” level hierarchy data model for SQL-based OLAP use cases, where each level is persisted as its own column. But here, instead of appending columns per level, we’re instead appending records per level.)
The logic, in SQL, for querying potential contracts that conflict with Season 4 exclusivity would then look something like this, i.e. a quite simple/reasonable query with nothing more than a simple join and filter (well within the skills of your average app developer):
SELECT
…
FROM
CONTRACT_LINES CL
INNER JOIN NODE_LINEAGE NL_IP ON
CL.IP = NL_IP.PATH_NODE // check for any conflicts
WHERE
NL_IP.NODE = 'ST_S4' // for the user-requested IP We can easily extend this exact same model with a column HIERARCHY_TYPE and then persist the same type of data in the same structure for the other 3 hierarchies, i.e. Market / Territory / Language.
The query would then be updated as follows:
SELECT
…
FROM
CONTRACT_LINES AS CL,
NODE_LINEAGE AS NL_IP, -- IP Hierarchy (Node Lineage Model)
NODE_LINEAGE AS NL_MRKT, -- Market Hierarchy (Node Lineage Model)
NODE_LINEAGE AS NL_TERR, -- Territory Hierarchy (Node Lineage Model)
NODE_LINEAGE AS NL_LANG -- Language Hierarchy (Node Lineage Model)
WHERE
-- User-specified filter criteria
NL_IP.NODE = 'ST_S4' AND -- IP: Stranger Things, Season 4
NL_MRKT.NODE = 'IFE' AND -- Market: In-Flight Entertainment
NL_LANG.NODE = 'ALL' AND -- Language: All Available
NL_TERR.NODE IN ('USA_NE', 'CA_CENTRAL') AND -- Territory: USA Northeast, Canada Central
-- Filter all upstream/downstream hierarchy nodes from the lineage table (aliases) via inner join
CL.IP = NL_IP.PATH_NODE AND
CL.IP = NL_MRKT.PATH_NODE AND
CL.IP = NL_LANG.PATH_NODE AND
CL.IP = NL_TERR.PATH_NODE AND
-- Don't forget to filter each alias accordingly
NL_IP.HIERARCHY_TYPE = 'IP' AND
NL_MRKT.HIERARCHY_TYPE = 'MARKET' AND
NL_LANG.HIERARCHY_TYPE = 'LANGUAGE' AND
NL_TERR.HIERARCHY_TYPE = 'TERRITORY'
;(For simplicity, all join conditions are specified as WHERE clauses above)
Not only is this code much simpler and easier to read than multiple, bi-directional, complex recursive functions, it’s also quite a bit more efficient:
Recursive logic is replaced with more efficient equi-joins and filters
Only query results need to be returned to the application logic - no need to load full tables
Only relevant contract lines are returned - no need to iterate over the entire table
While we haven’t dug deep into data overlap logic or potential nested for loops, what we can propose now is only needing N number of iterations (instead of M * N), where N is the number of deal parameter records - and in each iteration, declaratively compare the deal parameters with the full set of contract lines.
(In reality this can be further optimized with full declarative set logic, i.e. no looping whatsoever - but that’s for a future article.)
So, at this point, we’ve effectively achieved the goal of the article, i.e. walked through the details of an alternative data model, outside the realm of “traditional” OLTP patterns, that a software architect could (and should) introduce to simplify the code and accelerate the performance of critical enterprise applications.
Stick around though, for a more interesting and relevant reflections.
Thinking Like a Data Engineer
I want to briefly touch on how I would describe the thought process I went through when originally arriving at the data model above, as a way to try and help software architects wrestle with new perspectives on problems like these.
In the case of the CRM business logic described above, a key distinction becomes clear that differentiates this use case from other hierarchical use cases (and corresponding business processes):
A majority of business processes take place at the leaf nodes of hierarchies, whereas
the CRM IPM Rights Availability use case above takes place at any node of any of the hierarchies.
Let’s walk through this distinction with some common examples, highlighting how frequently business transactions take place at leaf-level hierarchy nodes:
When you buy apples at Wal-Mart, you’re buying at the product level, i.e. leaf level, of the product hierarchy: Apple → Fruit → Produce → Grocery
Each Wal-Mart store represents the leaf node of a territory hierarchy: Store → City → District → Region → Country
Retail sales, like buying apples, take place at a moment in time, i.e. a timestamp, which is the leaf node of a time hierarchy: Timestamp (Millisecond) → Second → Minute → Hour → Day → Week → Month → Year
In enterprise sales, revenue per salesman / saleswoman takes places at the leaf level of an org chart, i.e. Individual Contributor (Salesman) → Manager → Director → CRO
Revenue and Expenses are captured against the leaf nodes of profit center and cost center hierarchies, i.e. individual profit / cost centers, in financial reporting.
Labor expenses on large projects are assigned specific Project IDs in time tracking systems, i.e. the leaf nodes of work breakdown structure (WBS) hierarchies
So in the case of CRM IPM application, the default thinking of the original developers was to stick with the traditional parent-child (adjacency list) model, since that’s the standard “best practice” for modeling hierarchies, without thinking further about the fact that sales negotiations in the M&E business can take place across any level of any hierarchy - thus, the need and benefit of a data model that maps any given node to all of its upstream/downstream nodes in its lineage.
I’ll briefly address two concerns that the astute reader may be wondering about:
Doesn’t this data model explode the data and thus introduce its own performance challenges and storage costs?
In terms of data velocity, if logic is needed to recursively ETL the source parent-child hierarchy into this node lineage model, isn’t there a risk that any batched loads can fall behind, i.e. live sales negotiations miss the latest and greatest data?
These are valid concerns, but both are fortunately easily accommodated here:
In production, each of these models didn’t exceed record counts beyond six figures each, well within acceptable performance in any modern database.
Consider the hierarchies from a business perspective.
Classification of languages rarely changes.
Media/markets might change a few times a year.
IPs change approximately once a day.
Territories also change quite rarely.
So, event-based or trigger-based ETL on any modern system will capture changes sufficiently fast.
Conway’s Law & System Architecture
Now, there’s another elephant in the room, and this one is bigger.
CRMs are enterprise systems, tightly managed by vendors, and often completely inaccessible when managed as SaaS systems. Thus, software teams - and even their Software Architects and other leaders - often cannot be blamed for moving forward with bad architecture and/or bad data models “because they have to”.
So, what should they do? What can they do?
I’ll extend my contention at the beginning of this article by saying that not only should Software architects sharpen their data modeling skills, but they also should be regularly collaborating with Data Engineering colleagues to help think outside the box and explore alternate solution patterns.
In this particular case, there’s clearly a need to ETL the source data into the node lineage model, but moreover - the declarative logic described thus far lends itself to analytical databases, i.e. given the star schema structure, equi-joins, and filters (and additional date overlap logic I’ll get to shortly).
So, even though this isn’t a traditional analytics use case as such, the solution is a relatively straightforward data architecture, where the data model and refactored (declarative) business logic are pushed into an external analytics database, with no need to modify the source system whatsoever (other than whatever configuration is required to support data extraction, replication, CDC, etc. to get data out).
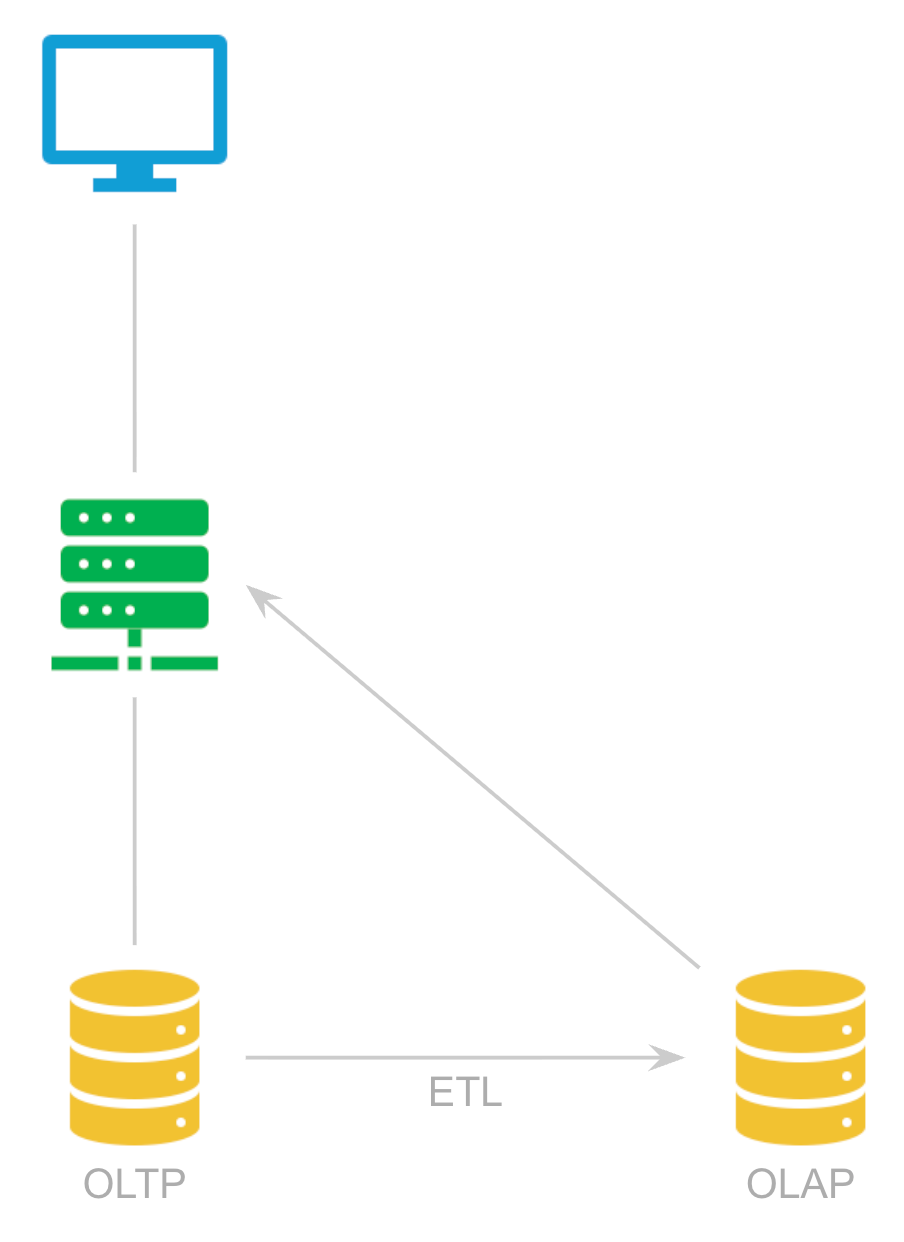
All it takes is a bit of thinking outside-of-the-box (and outside-the-org-chart) to overcome the artificial and bureaucratic limits imposed by Conway’s Law to implement a creative yet elegant data model and data architecture that drastically improves performance optimization, user experience, and developer productivity - at the cost of nothing more than some creative thinking, a bit of ETL, and DuckDB on an EC2 instance.
(To the purists of the data engineering world - forgive my cavalier use of the term OLAP - it simply makes diagrams like these simpler…)
Conclusion
To briefly summarize what we discussed in this article:
We walked through the supply side of the business model of major studios like Netflix, stepping through how content sales are negotiated across a few key (hierarchical) dimensions include IP, Market, Territory and Language. We then mapped these dimensions to a corresponding CRM IPM data model.
We discussed the business logic required when negotiating exclusivity, i.e. the basic idea of how to look for conflicts across the different hierarchies as described in the CRM data model.
We then reviewed the performance bottleneck that results from bad source data models, recursive algorithms for bi-directional hierarchical traversal, and the final straw of performance degradation which is nested for-loops.
We then teased out the crux of the problem, i.e. business logic in the CRM IPM application that takes place against nodes at any level of the given hierarchies, not just leaf nodes - which is quite unique compared to most business processes (which typically only take place at leaf nodes).
Then we proposed a data model that better corresponds with such a business process, maps to nodes at any level of the given hierarchies,
And lastly, we introduced a new system architecture, overcoming real organizational / bureaucratic / architectural challenges, by leveraging a simple data architecture from the world of data engineering to much more easily accommodate the data model and business logic changes recommended for optimizing performance, and at extremely low cost.
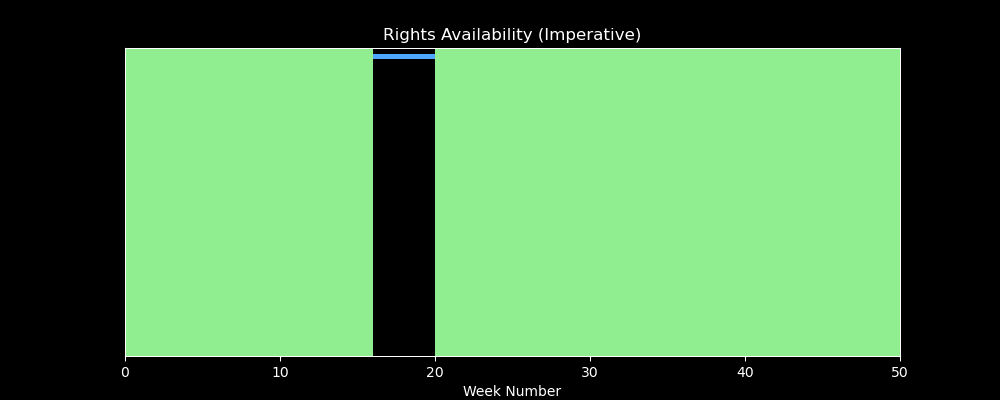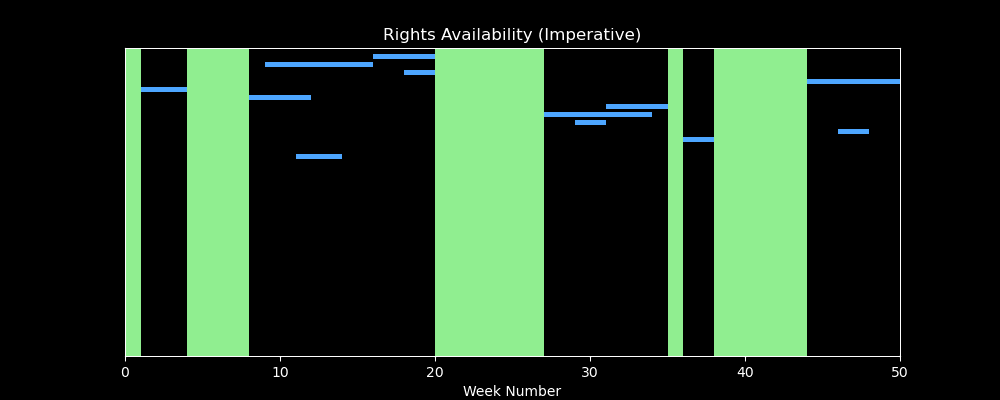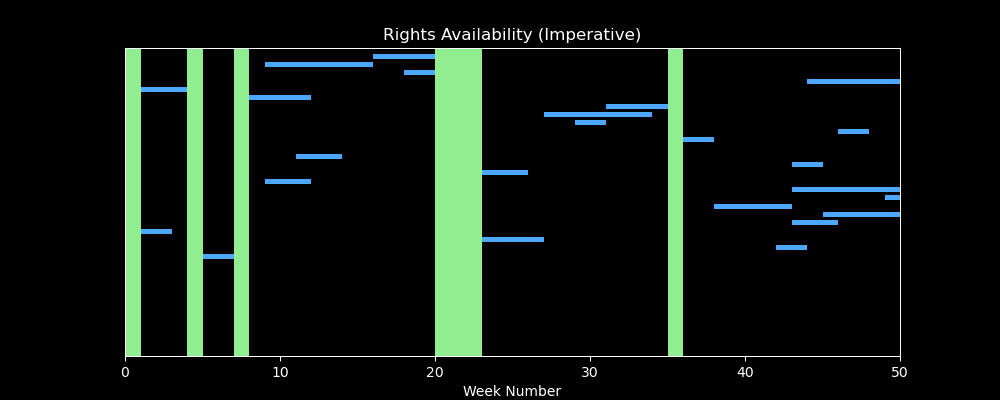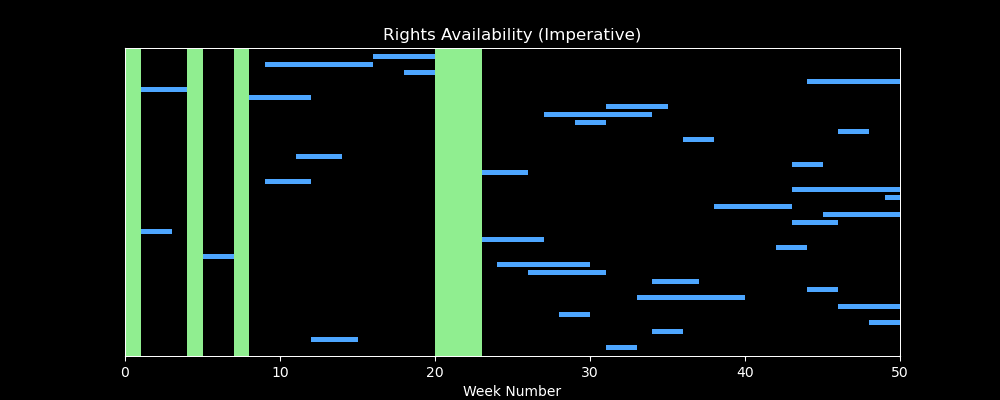
The last question to address then, back to the business logic is: how do you refactor imperative (potentially nested) looping logic when compare date intervals between the contract lines and deal parameters we looked at earlier, into something that is fully declarative that can then also refactored and pushed down into SQL in your OLAP system?
We’ll tackle that problem in a future article, but for now - enjoy this visualization that shows what the (badly performing) iterative solution looks like, i.e. identifying windows of availability in green as it loops over contract line records (blue time intervals below)…
A Final Caveat
When I solved the problem described above in real life, I didn’t actually come up with any specific name for what I’m here calling the “node lineage” model. When quizzing Claude on ideas for what to call it, I was informed that there’s already such a model in the literature referred to as a closure table. Which makes me feel things, like:
Kind of dumb, for completely reinventing the wheel.
Kind of smart, for completely reinventing the wheel.
Kind of dumb, for being outsmarted by AI.
Kind of optimistic, for the real opportunity AI introduces for empowering even advanced developers to get even sharper with their craft.
I decided not to mention this in the body of the article, as I want to try and share the thought process and enthusiasm of when I solved this problem for the first time. And I’m also assuming such a data model is relatively rare, as I never learned about it during my degree, nor have I ever heard the term in my 15+ years of data engineering, nor is there a dedicated Wikipedia article for a closure table… but yeah, it’s a thing, and it pre-existed what I thought was my own clever idea. :)
Thanks for reading!
Very in depth take on a complex concept!